

GBLシーズン「めくるめく記憶」でACE到達

今日、GOバトルリーグでACEに到達。
3/14に初期レート1790。109/225と大きく負け越してたので、そりゃそうだ、というレート。
…にしても過去最低だと思う。
その後今日まで1700〜1800をうろうろして、1900に乗ったのが2回ほどというテイタラク。
今期は諦めかなあ、と思ってたら、古巣の仲間でいまはポケGO仲間からパーティを教えてもらって、ファンタジーカップという特殊レギュレーションで大きく勝ち越し。レート2005、ギリACE到達となった。
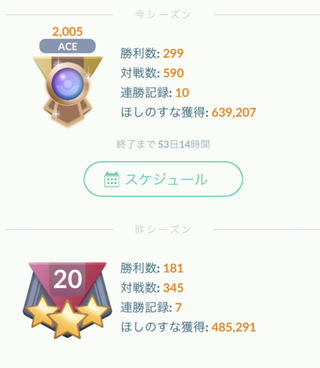
スクリーンショットで一目瞭然。前シーズンはレート戦のない調整シーズンということもあって、モチベーションもあがらず、GBLはあんまりやってなかった。
やっぱりレートの上がり下がりがある方がモチベーションになる。
前から言ってるように、対人戦はやってる最中、いろいろ考えなきゃいけないんで、ボケ防止になるしねー。
OCRのデータを電書用のテキストに変換する

国立国会図書館のOCRデータをepub3のリフロー型電子書籍にするためにテキスト化する下準備の覚え書き、が今回のエントリ。
印刷書籍から電子書籍にする時のボトルネックが「改行」処理。OCRうんぬんだけじゃなくて、インデザなんかのデータも一緒。
(いわゆる「空行」の扱いなんかも面倒くさい)

画像の出典:ボブ・ショウ 著 ほか『去りにし日々、今ひとたびの幻』,サンリオ,1981.10. 国立国会図書館デジタルコレクション https://dl.ndl.go.jp/pid/12632736 (参照 2026-04-08)
↑ このページをOCRで出力したテキスト↓

「一行」の扱い。
OCRでテキスト化したものは印刷書籍の「見た目の一行」が、そのまんま。
印刷書籍は「版面」という箱に、決まったサイズの文字を流しこんで並べるので問題はない。でも、電子書籍は「版面」みたいな決まった大きさの箱はなくて、文字サイズも決まっていない。
なもんで、見た目の一行通りに並べると、下のテキスト画像のように、文字の長さと表示部分の長さの不一致で無駄な余白が出たり、折り返しが不自然になったりする。
印刷書籍は「表示行」(物理行、レイアウト行とも言われる)
→ 一行は見た目の一行。
電子書籍は「論理行」
→ 一行は「改行」で区切られる/終了する。
電子書籍では、表示部分の幅や高さとは関係なく、「文章」が完結したところまでで一行になる「論理行」が必要。
【表示行1】「なかなかいいアイディアじゃないか」つやつやと光る壁を見まわしながら言う。「だけど、ひ
【表示行2】とつ欠点があるな、ジョン。これではどんどん部屋が狭くなっていく。そのうちすっかり隙間が
【表示行3】なくなってしまうぞ」
↑という3行の表示行を一行の論理行にする↓
【論理行】「なかなかいいアイディアじゃないか」つやつやと光る壁を見まわしながら言う。「だけど、ひとつ欠点があるな、ジョン。これではどんどん部屋が狭くなっていく。そのうちすっかり隙間がなくなってしまうぞ」
うまいやり方、これで決まり! というのも思いついてなくて、データの表示行(1行の文字数43字)を一行ずつを見て
- 表示行の文字数いっぱいなら、次の表示行に繋っている
- 表示行の文字数より短かかったら、そこに「改行」が入る
ということで、期待したところで「改行」された論理行の一行になる。
(表示行の文字数と「文章」の文字数がたまたま同じだったら、改行されなきゃいけないところなのに繋がってしまう…これはもう目視確認するしかないかなあ)
もうひとつ「空行」問題がある。
データに「改行」がないんだから、当然「空行」など存在しない。
そのために、OCRが出力するデータはテキストだけじゃなくて、JSON、XML形式のものがある。
以下はXML形式。
<LINE TYPE="本文"
X="1178" Y="362" WIDTH="129" HEIGHT="5430" CONF="0.935" PRED_CHAR_CNT="1.000" ORDER="25" STRING="「なかなかいいアイディアじゃないか」つやつやと光る壁を見まわしながら言う。「だけど、ひ" />
JSONもXMLも「表示行」のX座標Y座標が入っているし、XMLの方には「TEXTBLOCK」というテキストの塊ごとに、そのエリアのサイズについての情報がある。
→ 最初のスクリーショットの赤囲み部分。
<SHAPE>
<POLYGON POINTS="6500,551,6500,5820,7038,5820,7038,551" />
</SHAPE>
エリア四隅「左上,左下、右下、右上」のXY座標
このX座標(タテ書きの場合)の間隔を見て「空行」を判断するしかない、ここが広ければ空行。
基本、見開き単位の一段組とすると、ひとつのXMLデータには2つのTEXTBLOCK。
TEXTBLOCKの数が2つ以上あったら、タイトルや空行が入ったページ、ということでwarningを出して注意喚起。元の画像やPDFを目視確認して手作業で空行を入れる。
以上で、コマンドライン一発で完成とはいかないけど、ある程度流れ作業にすることができた。
この手順で、電子書籍化したのが先日のエントリ。
『去りにし日々、今ひとたびの幻』の表紙絵
https://t2aki.doncha.net/?id=3078

もう少し納得いくものになったらホームページの方にコードを掲載しておこう。
それよりなにより、こんなのをSNSに投稿したら多くのリアクションいただく今のご時世。
次々と公共の資源を潰していってる政府だし、国立国会図書館といえど安心してられない、かも。
新自由主義?ネオリベだっけ?とかでいつ有料になるかわからないし、なんならKPIがどーたらいいだして閉鎖されたらかなわない。
今のうちに所蔵・公開してくれてる本をPDFでダウンロードだけしておこうと思う。
国立国会図書館の膨大で貴重なデータをぜひ! 活用させてもらいましょう!!
『去りにし日々、今ひとたびの幻』の表紙絵

国立国会図書館のPDFからOCRをして、テキストを引っ張り出せたので、ボブ・ショウの『去りにし日々、今ひとたびの幻』電書化のメドはたった。
そしたらやっぱり欲しいのが表紙画像。
タイトルだけじゃ寂しいし、かといって、というか、もちろんわたしは表紙絵なんて描けない。
てことで、AIに描いてもらったのがこれ。

ボブ・ショウのスローガラスを知ってるひとならわかってもらえる…かなあ、よねえ。
ちょっとビックリした。
絵面はテキトーでありえない構図なんだけど、スローガラスじゃないか!? これ!?
google colab の stable diffusionに渡したプロンプトが以下
High quality concept art,A spacious study with large windows, In the countryside are several large, glittering glass panels,rim light,wide angle,sharp focus,highly detailed,digital art illustration,art station trending,playstation5,4K
A.I.ってそれっぽいのを出してくるなあ。
[04/06 15:10:24]
てことでepub3電子書籍にした!
iphoneのkinoppyの本棚に登録していつでも『去りにし日々、今ひとたびの幻』を読める
表紙にタイトルを入れるのに、ひと苦労だった。

電書作成のスクリプト流用でスグだろうと思ったら、OCRの出力するデータ構造の把握が手強い。まだバグってるんで、これも「また今度」案件にしておこう。
なにはともあれ、サンリオSF文庫を読める、というのは素晴しい。
トム・リーミイの『サンディエゴ・ライトフット・スー』『沈黙の声』なんかもデジタルアーカイブにあったし、まだまだいっぱい楽しめる、ぞ。
国立国会図書館のOCR Liteを使ってみる
サンリオSF文庫が読める国立国会図書館のデジタルアーカイブ。
国立国会図書館のデジタルアーカイブの本をOCRして(?)テキストを引っ張り出す、というのが今回のエントリ。
先日書いたように、これは各ページを画像として保存したもの。WEBで読みやすいようにページが工夫されてるんだけど、やっぱり手元、ローカルで気軽に読みたい。老眼に優しく文字サイズも調整できるepub3電子書籍にしておきたい。
そのためには「画像で保存されている文章」をテキストにする必要がある。そしてなんと!国立国会図書館では画像で保存されている文章をOCRによってテキストにするツールを公開してくれている。
NDLOCR-Liteアプリケーションのリポジトリ
https://github.com/ndl-lab/ndlocr-lite
↑ こちらの
https://github.com/ndl-lab/ndlocr-lite/releases
「release」から、最新版のv1.1.3
「ndlocr_lite_v1.1.3_linux.tar.gz」
「Source code (zip) 」
をダウンロード。
まずは「ndlocr_lite_v1.1.3_linux.tar.gz」を適当なディレクトリに解凍。
「linux」というディレクトリに展開される。
linux
├── data
├── lib
├── ndlocr_lite_gui
├── python3.12
└── site-packagesこの中の「ndlocr_lite_gui」という実行属性のついたファイルをコマンドラインで叩くと立ち上がる。

デジタルアーカイブの画像をスクリーンショットして溜め込んだディレクトリを指定してOCRを実行すると、アウトプット用に指定したディレクトリに「テキスト」「JSON」「XML」の3種類のファイルが保存される。
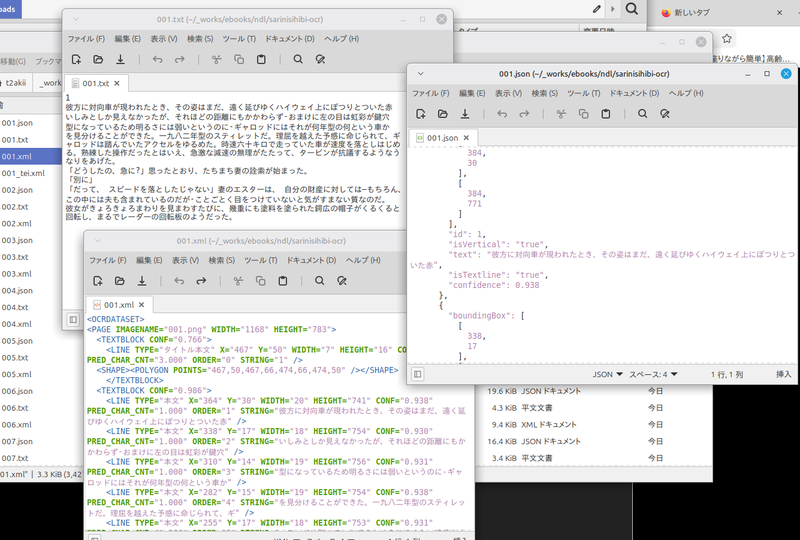
今回114枚の画像で、だいたい17分ぐらい。
PCはMac mini Mid 2011
OSはLinux Mint
・ルビや圏点は反映されてない(?)
・JSONやXMLにはレイアウト、位置情報が入ってるっぽい。
epub3の電子書籍にするので、テキストだけで問題はない。ルビや圏点がなくても、わたしは大丈夫。そのうちきっと解決してくれると思う他力本願寺。
これだけでテキスト化できて、操作画面を見ながらこまかい指示を必要ともしないんで、コマンドラインで実行できるようにした。
ただ、わたしはpythonについてまったく知らなくて、何かあったら困るので調べ物。
「Source code (zip) 」を適当なディレクトリで解凍する。
「ndlocr-lite-1.1.3」というディレクトリ以下に展開される
ndlocr-lite-1.1.3
├── LICENCE
├── LICENCE_DEPENDENCEIES
├── README.md
├── dummy.dat
├── ndlocr-lite-gui
├── pyproject.toml
├── requirements.txt
├── resource
├── src
└── train展開されたディレクトリに移動して以下のインストールが必要。
ndlocr-lite-1.1.3$pip install -r requirements.txt
ということだけど、わけもわからずインストールして、現在の環境に変な影響が出たら困る。
pythonは仮想環境で利用する(?)こともできるとのことなので、仮想環境を使うために以下をインストール
ndlocr-lite-1.1.3$sudo apt install python3.12-venv
インストールが終わったら
ndlocr-lite-1.1.3$. .venc/bin/activate
と叩いて仮想環境に入る
→コマンドプロンプトの左端に「(.venc)」と表示される。
(必要なものは「.venc」ディレクトリにインストールされるっぽい)
仮想環境に入ったことを確認して、上記の「pip」コマンドで必要なものを改めてインストール
「ndlocr-lite-1.1.3/src」ディレクトリに移動してndlocr-liteのpython3のコマンドを叩けばOK
- --sourcedir
スクリーンショット画像の入ったディレクトリ - --output
テキストなどが出力されるディレクトリ
各ディレクトリはどこでも大丈夫。わたしは相対pathで指定した。
ndlocr-lite-1.1.3/src$ python3 ocr.py --sourcedir ../../image-out --output ../../_tmp
コマンドラインの方が気持ち早かった…かも。
指定したディレクトリにGUI版と同じものが出力されていた。
作業が終わったら仮想環境を抜ける。
ndlocr-lite-1.1.3$deactivate
テキストにさえなってれば電書化はそれほど難しくない、かな。
…冒頭一字下げや空行がなくなってるんで、そのあたりの判定をどうにかしないといけない。
とはいえ。
これで、絶版となって今は読めないサンリオSF文庫が読み放題だ!!
今回、真っ先にテキスト化したのは、ボブ・ショウの『去りにし日々、今ひとたびの幻』
https://dl.ndl.go.jp/pid/12632736
これが読みたかったんだよなあ。スローガラスというアイディアから広がるドラマがたまらない傑作。
ちなみに、この作業の中でページのスクリーンショットを撮るには。
個人向けデジタル化資料送信サービス
https://www.ndl.go.jp/use/digital_transmission_individuals
わたしは「本登録」済みなので
>「公開範囲」が「送信サービスで閲覧可能」「国立国会図書館内/図書館・個人送信限定」
の本は「印刷」できる=PDFファイルとしてダウンロードできる。
※一回100コマまで
PDFにすればあとはImageMagickの出番なんだけど、今日時点コマンドがよくわからないんで、手作業で1ページずつスクショしたというテイタラク。
これはまたそのうち、だなあ。
そういや。
「OCRする」って、「インターネットする」と似てるような…
OCRって「する」ものなんだろか。言葉を雑に扱ってる自覚はあります、すみません。
[04/05 08:30:27] 追記
印刷用PDFがでかすぎて、うちの貧弱な環境だとメモリが足りない。
GIMPはエクスポートをポチっとクリックしたら戻ってこない。
ImageMagickは
>convert-im6.q16: cache resources exhausted
で、終了する。
[04/05 16:47:09]追記その2
pdfseparate でPDFを1ページずつにバラして処理すれば、ImageMagickで期待どおりに画像に変換される。
convert
-density 300
-units PixelsPerInch
-quality 90
-profile JapanColor2011Coated.icc
-colorspace cmyk
-profile sRGB_v4_ICC_preference.icc
-colorspace srgb
-crop 8712x5990+759+527
pdf/0001001.pdf
image/001.png
> -density 300
コレは、いわゆる印刷レベルのクオリティ。さすがに時間がかかる。
(-quality 90 はjpeg画像用で、pngを生成するのに関係ないけど、ついでに入れてても害はなさそうなのでなんとなくそのまま)
あちらこちらで昔から言われているように。
lmageMagickは何でもできるんだけど、コマンドラインオプションが順番も含めてわけわかめ(死語)
[更新]2026-04-05 16:52:13
手書きで字を書こう、絵を描こう!
パソコンのキーボードばかり、自分で字を書く機会が本当になくなった。老眼も進んで手元が怪しくて自分が何を書いて/描いてるのかよく見えなくなってる。
あきらかに40代の頃より字が汚なくなってる。もともと字が汚ない自覚はあるんだけど、それ以上に酷い。
エロ本編集をやってた20代の頃、穴埋め記事のイラストなんかを描いてたこともあった。それが今や絶望的に絵が描けない。
…てなことを痛感するんで、先日、無印のセールで2mmのシャーペンを買ってみた。これで少しずつでもいいから毎日「手書き」していくぞ、というのが今回のエントリ。
とりあえず。「ひとめに晒す」ことがだいじ。今さら恥もくそもない。

3次元を2次元に落としこむんだけど、脳ミソがテキトーなインチキ補正をしてしまう。
手先と脳が共謀して手抜きしやがる。
じっと我慢して対象を見て余計なことを考えずに、目の前にある・見てるものをそのまんま描きたいのに、手抜きしてラクな方に逃げてる・飽きてる。だからイイ加減なものになってしまう。
線がどうしたとか以前の問題だった。ただただ、雑なだけ。

字が汚ないのも同じ、というか絵より酷い・根が深い。
単純に、ちゃんと字を覚えてない/忘れてる。なもんだから、うろ覚え、形で「当たらずしも遠からじ」ぐらいで脳ミソが妥協してる。
元を知らずに再現できるわけがない。だから字が汚ないというより、字になってない。

わたしの大好きなベーやん(ベルゼブブ優一)をモデルに頑張る