

web本棚のソースコード公開

今まで、スクリプトのソースコードを晒すことはしてなかった。
いや、ぶっちゃけ、自分で見ても酷いありさまで、とてもひと様に見せるようなシロモノじゃないから。
そんなものを公開したところで、誰のためにもならない・誰の役にも立たない。
…ということなんだけど。
還暦も過ぎるといろいろ終活を考えなきゃいけない。
先日のエントリ 「web本棚」 でも終活の一環でサービス終了ということを書いていて、ちょっと考え直した。
書き散らかしてきたスクリプトを晒したところで誰のためにもならないけど
「晒すことで自分のやってきたことを自分でふりかえることになる」
のは、自分のためになる。単純に面白い。
ということでちょっとずつ晒してみようかとホームページに新コーナーを作った。
まずはweb本棚のソースコードを公開
「web本棚のソースコード::On Golden Pond」
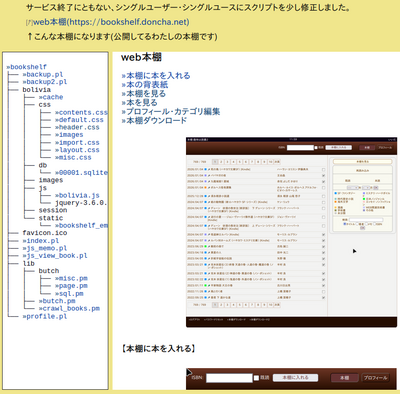
もう20年ほど前に作って、改築増築改修をしてきたもの。
SQLもまだ覚えたてみたいな時で、今だったらjoinしてgroupingしてとかSQLだけで済ませられるようなことも、ひとつずつ抽出して、抽出した結果をperlで処理してる。
なかなか恥しいシロモノなんだけど、怪我の功名というかSQLが単純なので処理の切り分けがperlのところで済むので簡単に改修できる。
とはいえ問題がjavascriptとスタイルシート。
javascriptはjQueryなんか使っててそのままだし、スタイルシートがjQueryべったりで、スマホ対応が無理。これは諦めた。
・本棚を眺めてるというのにページ遷移なんかで読みこみが入るとうっとーしーからアクションを起こしてもその場から極力動かずに済むように
・没頭してると時間を忘れそうだから時計表示は必須だろうし
などなど、どうしても(当時としては)jQueryが必要だったんだよなあ。失敗だった。
ソースコードを公開するなら、今どきなら、プログラマ御用達のgithubやcodebergを使うんだろうけど、わたしはただの素人でプログラマではない。
それに不具合やリクエストが飛んできても対応できない…というか、その気もない。
文字通り、素人のクソコードを本職のプログラマが利用するようなサイトに掲載する度胸もないしね。
なので、自分のホームページでそっと公開することにした。
自分のホームページなら、何をするにしてもすべて自分の管理下、ほかの誰かに迷惑をかけることもないという気楽さもあるしね。
[更新]2026-02-02 13:33:28
web本棚
20年ほど前、2006年4月1日から公開しているweb本棚がある。
ブログブームがひと段落して、mixiなどのSNSが話題になって、次はSNSですよという頃だった。
既読/未読がわかって、本をダブって買わないために、という本棚を作ってたところで、それなら本棚の共有サイトを作ってサービス公開してみようというのが始まり。
『趣味は読書2』
図書館で本を借りて図書カードを見て
「あれ?あのコもこれ読んだのかぁ」とか「おっあいつこんなの読むんだ」と、ニマニマしたり
ひとんちに呼ばれたら、まず本棚を覗いて
「これ、わたしも読んだよ」と言いたくなったり
図書館とか本屋で、どの棚の前に立っているかで、そのひとの属性がわかって、うれしかったり
なんだか「ありきたり」な趣味なので履歴書にも書けない気がしたり
本を読んでも難しいことを考えたり感想文は面倒くさかったり
ヲタクだと思われそうで嫌だったり
でもって、だけど本好きとか本読みですが、なにか?
というようなことを、思ったことはありませんか? ぼくは、あります。なので、そんな本棚のようなサイトを作ってみました。
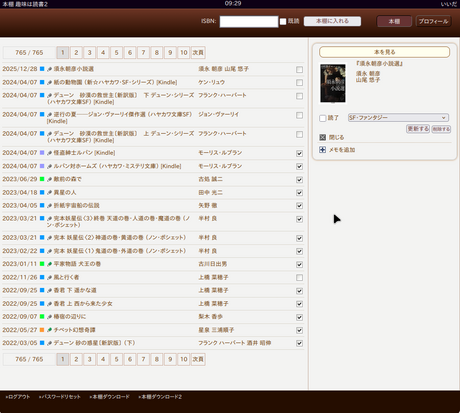
たぶん、WEB本棚サービスとしては早い方だったと思う。500人弱のユーザーのかたの登録で、アクティブなユーザーさんは20人弱ほど。
最初は自宅のPCでサーバーを立てて公開して、311の震災をきっかけにレンタルサーバーに引越し。
現在もまだ稼動中なんだけど、新規登録を中止して、いま利用してるかただけの運用になっている。
ただ、わたしの還暦を過ぎた年齢的にもうそんなに長く続けられない。
んなこんなで、レンタルサーバーの契約が切れるタイミングでサービス終了することにした。
利用しているユーザーさん向けにサービス終了の告知とバックアップのお願いを表示。
とはいえ、せっかく登録・利用してもらってる本棚だし、バックアップではなくて本棚の復元ができるようにスクリプトを改修した。
ローカルPCでやるにはapacheやperlが必要だったり、web版(レンタルサーバー)だと有料だろうし、ハードルが高くなってしまったけど、復元手段を用意できたので案内と手順書も告知した。
どのぐらいのユーザーさんが使ってくれるか、難しいところだけど、これでひと安心。けっこう気になってたんだよね。
もともと、ユーザーさんの行動を見ると、本棚にアクセスして、登録したら離脱、というのが90%以上。
ほかのユーザーさんの本棚を見にいくとかお気に入りに登録するという「交流部分」はほぼほぼ使われてなかった。
上記したように、もともと「未読/既読」の確認のための本棚というのがスタート。
電子書籍なんかだと「購入履歴」が残るので、当初の役割がなくなってわたし自身があまり使わなくなっていた。
だいたい、老眼が酷くなってきて文字を読むのがつらくて読書量が激減してるんだけど。
とはいえ、シングル利用向けに作り直してみたら面白いんで、また使ってみようかと。
本棚なんて個人情報をネットで晒すのもどうなのと思われそうだけど、好きな本や映画のタイトルを並べて自己紹介がわり、ということもあるだろうし。
閲覧するだけならログイン不要の本棚ということにした。
↑わたしの本棚…ほんとろくに読んでない(登録してない本もあるけど)
この際、せっかくだし「老眼鏡」を作ろう。
ちなみにweb版のスクリプト一式はこちら
https://bookshelf.doncha.net/arc/bookshelf.zip
ファイル、ディレクトリ構造そのまま。perlの実行属性を705か755にすれば動くと思います。
v1.0.1[[2026/01/05 15:57:31]]
・kindle本の登録ができなかったのを修正
・本の情報に取得できなかった場合のcache設定修正
ひとを巻き込んでサービスを公開するのはいいけど、終了させる方がいろいろ大変。
これもまた終活の一環だなあ。
[更新]2026-02-02 09:22:01
スパイダーマンとか古処誠二とか
昨日はスパイダーマン・アクロス・ザ・スパイダーバース
いやもう評判以上で2時間半ほどもうバクバクうるうるしっぱなしだった。
大切なひとを守るために頑張っていて、大切なひとを守るために頑張ってるひとを全力で応援するひとたちがいて、という王道、ド直球。
昔っからわたしは家族の話に抵抗力がなくて、すぐに涙腺がイッてしまう。
そこにもってきて、週刊少年ジャンプだ。仲間が集結して応援するんだからもういかんかった。
マルチバースの均衡を保つためvs家族もマルチバースも守るため、という図式。
ツッコミどころとしては、え?それってミゲルが始めちゃったんじゃないの?というのがあって、グウェンのお父さんの仕事が?ピーターの子供にも?とかとかネタバレになるのであまり触れない。
キャラ的には今回の新キャラ、ドレッドヘアのホビーが美味しいところをもってく。もろ好みのタイプだった。
今日は古処誠二『敵前の森で』
やっぱ間違いないがないなあ。傑作。
最近の古処誠二は『ルール』や『七月七日』の頃のようなウエットなところがないんだけど、みんながみんな、その時その場での自分の最善を尽くしたその結果、という軸はブレず、本書もホント熱い。冒頭、佐々塚兵長のエピソードで始まるプロローグがめっちゃ効いてくる。というかみんなの行動原理がここに集約されてたんだということに最後まで読んで改めて気づかされて、じわ〜っと滾る。
良いフィクションの摂取ができた昨日今日だった。
て、2作ともわたし狙い撃ちされてた。
明日から週末にかけてはシフト仕事。
これがもうさすがに体力の限界なんだよなあ。朝シフトは4時起きだし、夜シフトは帰宅が0時を回る。還暦の体力でこんなシフトは無理。健康保険加入で人間ドックなんかがありがたいというか美味しいんだけど、そもそも健康を害するようなシフトなわけで、改めて見直すとこれって本末転倒。
てなことを今まではツイッターなどSNSでたらたら書き散らしてたんだけど。
みけさんもいなくなり、世界に向けて発信するぞ!みたいなこともないんで、昔に戻ってこっちに引きこもることにした。
SNS利用はこの雑記帖更新告知と、ゲームを進めるために作ったポケモンGOのツイッターアカウントだけにする。
ちょっと前にも書いたように、この雑記帖なら、書き散らかしたコンテンツの管理も自分でコントロールできるし、呆けてしまったり、死んでしまったりしたら、レンサバとの契約が切れてそれっきりで後腐れもないしねー

『敵前の森で』
古処 誠二
Chromebookで電子書籍を読む
正規のChromebookはgoogle playからアプリをダウンロードして使うことができる。
デスクトップやノートパソコンでAndroidアプリが使えるということになる。
やりたいことは。
ASUSのChromebook CX1101で電子書籍を読む、というか表示確認をしたい。
今のところ、ChromebookというかChromeOSで制作した電子書籍を確認するためには、
・WINDOWSのノートパソコンを起動して
・電子書籍ファイルを共有フォルダに保存して
・WINDOWS版のKinoppyを立ち上げて読む
これだけっちゃこれだけなんだけど、この「これだけのために」が面倒くさい。
手元のChromebookでそのまま確認できればらくちん。
てことで、ASUSのChromebook CX1101でも電子書籍を読めるように電子書籍リーダーを探してみた。
google play storeで確認したところ。
kindleとkinoppyはChromebookに対応していない。
kindleについてはgoogle play storeではなくて、Amazon アプリストアから直接ダウンロードすれば使えるらしいけど、いくつか手順が必要でそこまでやる?
https://www.itmedia.co.jp/news/articles/2206/15/news181_2.html
↑chromebookにamazon アプリストアをインストールする方法
大日本印刷のhontoがChromebookでも使える
https://play.google.com/store/apps/details?id=jp.co.dnp.eps.ebook_app.android
問題なくgoogle play storeからインストールできた。
すでにhontoで購入済みの本も本棚に同期されていて、すんなり読める。

ローカルの電子書籍、epubファイルを読ませるには、リーダーごとに指定された保存フォルダにepubファイルを保存する必要がある。
Andoroidアプリのhontoの場合は
/storage/emulated/0/Android/data/jp.co.dnp.eps.ebook_app.android/files/epub/
↑ここにファイルを保存する。
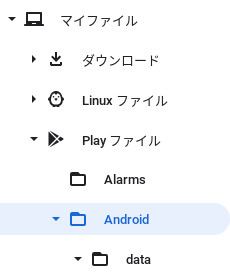
chromebookではどこに保存するのか探してみた。
chromebookの「ファイル」アプリで「マイファイル」→「Playファイル」
「すべてのPlayフォルダを表示する」にチェックを入れると出てくる
/mnt/chromeos/PlayFiles/Android/data/jp.co.dnp.eps.ebook_app.android/files/epub/
↑ここにファイルを保存する。
とりあえずはこれでOKかな。
ほんとは本体に保存するのではなくて、作業しているSDカードをlinkしたいところだけど、
ln -s
で権限がないとはねられる。Playファイル以下にあるフォルダ側の権限の問題っぽい。
最終的に納品前にkindle previewerでの確認も必要なので、WINDOWSを立ち上げることになるんだけど、途中途中のちょっとした確認はこれで手間がずいぶん省ける。
電子書籍を自分が読む時はスマホなんだけどね。
昭和の書籍の文字サイズは老眼には厳しいんで、古本ではなくて、文字サイズを変更できる電子書籍がありがたいんだよなあ(ポンコツ)
書誌情報データを求めて三千里
一昨日、新元号の発表があった4月1日に国立国会図書館の書誌データAPIが解禁となった。
今までも検索などに使えていたけど、データベースとしてガツガツ使うには登録が必要だったり面倒くさかったのが、4月1日からは誰でも自由に使ってもかまわんぜ!になった。
てことで、今さら国立国会図書館の書誌データAPIをごそごそ覗いてみた。
国立国会図書館サーチについて>API仕様の概要
https://iss.ndl.go.jp/information/api/riyou/
わたしの、というかわたしが公開しているサイトの使い方は前にも書いた通り。
「ISBNをキーにして書誌データと書影URLを取得したい」
たとえば、スティーヴン・キングの『シャイニング』
ISBNは978-4167705633
これを国立国会図書館のAPIで探すには以下
https://iss.ndl.go.jp/api/opensearch?isbn=978-4167705633
→書誌情報のXMLが返ってくる
https://iss.ndl.go.jp/api/openurl?isbn=978-4167705633
→検索結果ページが返ってくる
https://iss.ndl.go.jp/api/sru?operation=searchRetrieve&maximumRecords=10&query=isbn%3d9784167705633
→書誌情報XMLが返ってくる(このsruはさらに細かく検索方法の指定もできる)
うちの場合、必要な書誌情報はopensearchで十分。
著者についてももろもろ考慮されて(同性同名や読みなど)おり、データのクオリティは信用できる。さすが。
https://www.ndl.go.jp/jp/data/faq/author.html
蔵書のある図書館の情報なども取得できるので、位置情報と合わせて「目当ての本がある最寄りの図書館」なんて検索も実装できるし、その手のアプリがすでにあるのは、国会図書館のデータが元ネタじゃないかな。
だけど、書影がないのはほんと残念。
本棚を眺める楽しみのひとつ、というか欠かせないのが表紙だもんなあ。
基本的な書誌情報は国立国会図書館で、書影・表示画像はamazonなどのショップサイトのURLを別途取得…とか1冊の本のために2回も外部にリクエストしてるとサイトの表示がもたつく原因になってしまう。
てことで、うちのサイトのデータ取得方法は現状のままとする。
国会図書館のデータはまた何か別の用途で利用させてもらおう。しっかりとしたデータは見ていて気持ちいい(データオタク)
ちなみに。
「一般社団法人 日本出版インフラセンター」という版元主導のところも3月25日に書誌データベースのサイトをオープンしたけど、APIもなく、手入力でポチポチ検索できるだけ、なのでスルー。

| << | 2026/3 | >> | ||||
|---|---|---|---|---|---|---|
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | ||||
【最近の10件】