

WINDOWS10にアップデートしたった

Inspiron 530Sという2007年発売のXPのデスクトップ。XPのサポートが切れるんで去年WINDOWS7にしたばかり。そして一昨日の晩にWINDOWS10への無償アップデートをしてみた。こいつはセカンドマシンなので割と気楽。
ネットの情報を見ると、動かなくなったアプリが!ドライバが!!周辺機器が!!!という悲鳴もあがっているんで心配だった。
でも、結論からいうと特に問題はなかった。
なんといっても、10年ほど前に買ったフォトショも、5年ぐらい前のインデザCS5も、イラレCS5も無事起動。このアドベ神様たちが動かなかったらまたナンボの出血になったことやら…ていうか、出血多量で死ねるんで、動かなかったらWIN7に戻した。
今のところ、引っかかったのは。
DELLの液晶ディスプレイS2240Lの解像度。
モニタなのか、ビデオボードのドライバなのか、最初起動したら画面が1024x768という昔懐しの解像度。
ディスプレイの詳細設定を開いて解像度を見ても設定可能な解像度は「1024x768」「1280x1024」の2択。少しでも広い方がと1280x1024にしたら横長の画面に引っ張られて、正方形のものも平たい長方形に引き伸ばされてしまった。
検索してみるとビデオ回りの不具合(?)WIN10未対応(?)の問題で起こっているようでQ&A系の記事やブログなどが多数上がっている。
デバイスマネージャーを見ると、ディスプレイアダプターのところに黄色三角のビックリマーク。
「Intel(R) G33/G31 Express Chipset Family(Microsoft Corporation - WDDM 1.0」
これはよくわからないまま解決した。
アップデートだなんだで、何度か再起動しているうちに問題なく表示可能解像度の選択肢が並び、今は、最大の「1920x1080」を選択できるようになった。
ディスプレイアダプターもビックリマークがついていた時と同じものなので、いったい何だったんだろう。WINDOWS10側でハードウエアを正しく認識できてなかったのかなぁ。
無線LANがブチブチ頻繁に切れる。
デスクトップで使ってる無線LANアダプタ、PLANEXのGW-USNanoはWIN7までの対応でWIN10は対応外。
そのせいなのか頻繁に接続が切れるし、なんだかネットが重い、遅い。5分ももたずに接続を切られたんじゃ今どきは何もできない。切れるたびにルーターの電源を抜いて再起動したり、ipconfigでIPを取得し直したり、キリがない。DHCPじゃなく手動でIPを決め打ちにしたら少し改善されたけど切れる間隔が5分から15分に伸びた程度。
ルーターのせいかとも思ったんだけど、他のPCやスマホやタブレットでは問題なくWiFiを掴んでいる。
なもんで、これは無線LANを諦めた。
LANケーブルと壁にくっつけるフックを買ってきて有線LANにした。
(ノ*マに行ったらWIN10対応の無線LANアダプタが見当たらなかった…)
んでWINDOWS10だけど。
新しい環境はそれだけで今は面白いので、そのバイアスのかかった状態だけど、かなりイイんじゃないか。
まずこのフラットデザインがいいし、EdgeがシームレスにOneDriveだのと繋がって面白いし、やっとMacのようにUIが統一されて使いやすくなってきたのかなあ、という印象。
WINDOWS7と比べて動作が重くなったという感じはしない、むしろサクサク感がある。
cmd.exe(コマンドプロンプト)は、当然Gow(ls や cpなどunixのコマンドラインツールのパッケージ)もperlも動いて今までどおりだし、xyzzy(エディタ)もImagemagickも問題なし。AltIME(CtrlキーとAltキーを入れかえるユーティリティ)もSKKFEP(かな漢字変換)も使える。
こうした細々とした日常生活に問題もなく、アドベ神様たちもそのまま使えるのでWINDOWS10へのアップグレードは大正解だったなぁ。
outlook.comのアカウントを取得してWINDOWS10にログインすると、他のPCやタブレットと同期がとれるのも面白そうだ。
…とはいえ、仕事で主に使ってるDELLのInspiron mini 1012をWIN10にするのはまださすがに様子見か。IE推奨というWEBの管理ページがあるんだよなあ。WIN10でもInternet explorer11が動くけどちょっと心配なので先方で確認とれてからにしよう。
[05/24 11:32:43]
IE推奨のWEB管理ページ、ちょっと作業したら問題なかったし、Firefoxでも問題なしだったんで、メインで使ってるネットブックのInspiron mini 1012もWIN10にアップデートした。
アドベ神さまたちは無事起動するし、各種ユーティリティも大丈夫。
apache(WEBサーバー)が起動しなかった。
WIN10ではデフォルトでIISが立ち上がってportを取っているのでapacheが弾かれていた。なので、IISを起動しないように設定したら無事apacheが起動。
コントロールパネル→プログラム→WINDOWSの機能の有効化または無効化→インターネットインフォメーションサービスのチェックを外す
動作に関しても、CPUはAtomだしメモリも2Gで非力なネットブックだけど、サクサク動くなあ。これもアップデートして大正解だった。
[05/24 20:20:51]
Inspiron miniが熱くなっていてCPU温度を見ると70度前後。特にアプリも立ち上げてないのに。
タスクマネージャーを見るとCPUの使用率が100%近くをうろちょろしてる。CPUを占拠しているプロセスを見ると「Windows Search Indexer」とその仲間というSearchFilterHost SearchProtocolHost。
ファンのないネットブックでこの発熱はまずい。
ということで検索してみたら、どうやらこのSearch Indexerが暴走しているとのこと。
「SearchFilterHost.exeの暴走原因はXml爆弾」エンジニア徒然草
http://mitaka1954.cocolog-nifty.com/blog/2014/05/searchindexhost.html
↑こちらが参考になりました。
xmlファイルのコンテンツ(中身・内容)をインデックスし損ねて暴走することがあるらしい…てバグやん。
まずは、xmlファイルが原因だということが判明した切っ掛けがiTunesのxmlファイルとのことで(最新のiTunesでは大丈夫らしいけど)もう使っていないiTunesをアンインストール。
次に
「コントロールパネル」の検索窓で「インデックス」を検索→「インデックスのオプション」「オプションの詳細」→「プロパティのみインデックスを作成する」(コンテンツをインデックスから外す)
これで無用な暴走は避けられるはずなので、インデックス作成完了後のCPU使用率を確認。
(↑indexerのCPU利用率激減ていうか、インデックスを再構築したらほとんど動きがなくなった)
[05/27 09:59:46]
WINDOWS10不具合メモ
Inspiron mini 1020で
「ファイルを右クリックするとエクスプローラーが落ちる」
「exeファイル」を右クリックしてコンテキストメニューを出そうとするとexplorerが落ちる(開いているフォルダが閉じて終了する)
exeファイルに限らず、exeファイルへのショートカットでも同じ。また、シングルクリックして、フォルダメニューの「アプリケーションツール 管理」で「管理者として実行」などをクリックしても同じ症状。
つまり、実行ファイル(exeファイル)はダブルクリックして実行することしかできない。
・ファイルのプロパティを見ることができない。
・管理者、別ユーザーで実行できない。
イベントビューアーを見ると
障害が発生しているアプリケーション名:exeplorer.exe、バージョン10.0.10585.306
障害が発生しているモジュール名:dtdll.dll、バージョン10.0.10586.306
ということらしい。
右クリックのコンテキストメニューの不要っぽいものを削除したんだけど解決しないなぁ。
…うーん、これは不便。
でもこの問題は、デスクトップInspiron503SのWIN10では起こっていない。
問題を起こすのは実行ファイル(exeファイル)だけ。フォルダメニューから管理者・別ユーザーとして実行しようとexplorerが落ちるので、実行権限、ユーザー設定で問題があるのかもしれない。
未解決
[06/01 10:41:28]
解決。
コンテキストメニューに入れていた「コマンドウインドウをここで開く」を殺したらエクスプローラーが右クリックで落ちることはなくなった。
具体的には。
http://gigazine.net/news/20070309_shellexview/
↑このツールで「CmdLineContextMenu Class」を「Disabled」にした。
Gow
https://github.com/bmatzelle/gow/wiki
ActivePerl
http://www.activestate.com/activeperl
xyzzy
https://github.com/xyzzy-022/xyzzy
ImageMagick
http://www.imagemagick.org/script/index.php
SKK日本語入力FEP
http://coexe.web.fc2.com/skkfep.html
AltIME
http://www.vector.co.jp/soft/win95/util/se027730.html

[更新]2016-06-01 10:41:28
ImageMagickでPDFをJPGに変換
CMYKのPDFをRGBのJPG画像に変換するのはImageMagickの以下のオプションをつければOKだった。
・解像度 -density とその単位 -units
→300ppi
・JPEG品質 -quality
→高画質 90
・4色のカラープロファイル -profile
→「JapanColor2001Coated.icc」を指定すればほぼ問題ない、はず。
・カラーモード -colorspace
→cmyk
・rgbのカラープロファイル -profile
→「sRGB_v4_ICC_preference.icc」と他ので差はなかった、かな。
・カラーモード -colorspace
→srgb
convert
-density 300 -units PixelsPerInch
-quality 90
-profile JapanColor2001Coated.icc
-colorspace cmyk
-profile sRGB_v4_ICC_preference.icc
-colorspace srgb
input.pdf output.jpg
上記をコマンドラインに一行で書いて実行すれば、複数ページあるinput.pdfを、連番がついたRGBのJPEG画像(output-0.jpg output-1.jpg)に変換してくれる。
プロファイルは以下のサイトからダウンロードできる(Macはrgbのプロファイルがシステムに入っている)
「ICCプロファイルダウンロード」
http://japancolor.jp/icc_download.html
「lnternational Color Consortium」
http://www.color.org/srgbprofiles.xalter
↑変換後の画像の一部(100%表示)。このぐらい文字がしっかりしてれば問題はない。
フォトショップでもPDFからJPEGに変換してみたけど、品質的に変わりはなかった。
(アクションを組めばフォトショップでも一括処理ができそう。…あ、フォトショて複数ページのPDFを全ページ一度に読みこめるんだっけか)
ついでにimagemagickのconvertのパラメータを検索したのでメモ。
サイズ変更
-resize と -geometry と -scale の3つ。この中では
-scale 1024x
の精度が高いらしい。同じことをするのになんでまた3つもオプションがあるんだろう。きっと何か意味があるんだろうなあ。
レベル補正
-level 20%,80%
↑山の両端を切り落とし
おまかせレベル補正
-auto-level
アンシャープ、シャープ
-unsharp 4x4+0.5+0
-sharpen 5
↑unsharpのパラメータはよくわからんので実際に数値を変えて、目で見ながらという地味な作業かも。
毎度のことながらimagemagickを使うたびにオプションやパラメータを探しまくり。imagemagickはオプションもパラメータもてんこ盛り。でもって、ネットの二次情報はオプションを間違えたまま掲載ということも…って、これだけどっさりオプションがあったらしかたがないわなあ。
ちなみに、プロファイルは各々どれを使ってもあまり差は感じられなかった…のは元のPDFの作りのせいだろう。
画像処理は負荷が大きいようで、DELLのWINDOWS7ネットブックは、変換のためにコマンドラインでエンターキーを叩いたらひーひー言いながらなかなか戻ってこなかった。EPUBファイルの制作はこのネットブックでやってるんだけど、変換処理だけは別のパソコンでやったほうがいい、か。うーむ。
[2016/06/11 10:15:20] 追記。
PDFをjpg画像に変換すると背景が真っ黒になってしまうファイルがある。
PDFなどの透明部分が黒になってしまうらしい。
オプションを追加することで背景を白にできる。
-alpha Remove
[更新]2026-02-01 09:10:34
paypalを使って電子書籍のダウンロード販売
電子書籍元年が何度もきたおかげで、電子書籍(デジタルコンテンツ)のダウンロード販売がDRMもついてAmazonや楽天kobo、iBookstore、KADOKAWA☆BOOKWALKERに並べることができる時代となった。
また、電子書籍専門というわけではなく、デジタルコンテンツをダウンロード販売できるサイトも百花繚乱雨後筍で、コンテンツさえ用意できれば個人で簡単に販売ができる。
「デジタルコンテンツをダウンロード販売できるサイトを比較してみた」
http://writing-san.blog.jp/archives/32017213.html
また、ワードプレスにはダウンロード販売のためのプラグインまであって、販売チャンネルの選択肢はたくさんある。
「Easy Digital Downloads - ダウンロード販売サイトを簡単に作れるWordPressプラグイン」
http://netaone.com/wp/easy-digital-downloads/
集客力販売力、販売手数料や手間ひまを考えて自分に合うところにコンテンツを置けばいいし、そうすれば販売ページへのURLや購入ボタンをSNSや自分のサイトに貼りつけて告知できる。
ぶっちゃけ、わざわざ自分でダウンロード販売の仕組みとか作るのは時間と労力の無駄なのでオススメしない。
面白そうだ、という好奇心自己満足。それと、もしかすると、何らかの事情で他社サービスにコンテンツを置くわけにはいかないような場合に。
てことなので、以下はわたしの技術メモ。備忘録。
内容的には2010年の雑記とPayPalとのやり取りなどはほぼ同じ。
「paypalと電子書籍のダウンロード販売(その1)」
http://t2aki.doncha.net/?id=1277017233
「paypalと電子書籍のダウンロード販売(その2)」
http://t2aki.doncha.net/?id=1277130006
今回の雑記では自サバ側のこともメモしておく。
【じぶんちでの設定】
コンテンツをサーバーの所定のフォルダにアップロード。
サーバーのデータベースにコンテンツの商品登録。ここで商品にIDを付ける。
以下3つのスクリプトを用意
・ご購入ありがとうございますページのスクリプト
・IPN受信&データベース登録用のスクリプト
・ダウンロード用スクリプト
【PayPalでの購入ボタン作成・各種設定】
「トップ」→「販売ツール」のメニューにある「売り手の設定」から
→「PayPalボタン」
[今すぐ購入]サンプルボタンあたりを雛形に「ボタンの編集」で商品名や値段などを入れる。ここではオプションの商品ID(=データベースで決められたID)を入れるのを忘れずに。
ボタンを作ったら「コードをコピー」して自分のサイトの購入ボタンを設置したいところにコードをペーストする。
→「ウェブサイトの設定」(ウェブペイメントの設定)
・ウェブペイメントの自動復帰「オン」
・復帰URL:ご購入ありがとうございますページのURLを記入
・支払いデータ転送「オン」※IDトークンをコピーしておく
・暗号化されていないウェブペイメントの受領拒否「オフ」
・PayPalアカウントオプションサービス「オン」
・連絡先電話番号「オフ」
・エクスプレスチェックアウトの設定「いいえ」
→「即時支払い通知」(IPN)
・通知URL:IPNを受信するスクリプトのURL
・メッセージの配布:有効
→「PayPalボタンの言語コード化」
・「詳細オプション」→「UTF-8」
【PayPalとのやりとり】
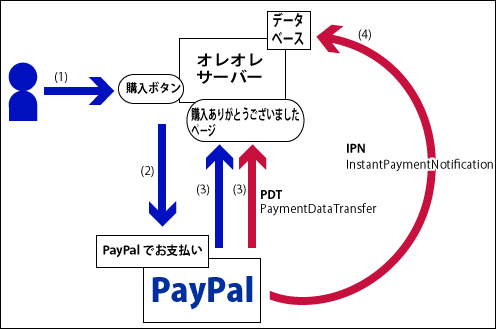
ユーザーの動きは以下の3つ。
1)ユーザーがオレオレサーバーの購入ボタンをクリックすると
2)PayPalの決済ページに飛んでそこでお支払い
3)お支払いが終わるとオレオレサーバーの購入ありがとうございましたページに戻ってくる。
ユーザーのお支払い終了と同時にPayPalからオレオレサーバーに購入データが飛んでくる。
購入データは以下の2種類。
データを取得して解析するためのサンプルコードがPayPalに用意されていて、そのまんま利用させてもらう。
3)PDT(Payment Data Transfer)
図では赤い矢印がひとつだけど、データのやりとりの実際は。
→PayPalからオレオレサーバーへ
・ユーザーが購入ありがとうございますページにリダイレクトされてくる時に、トランザクションを持ってアクセスしてくる
→オレオレサーバーからPayPalへ
・トランザクションと管理ページの「支払いデータ転送」の項目に記載されているIDトークン、コマンドをPOSTでPayPalにリクエスト
→PayPalからオレオレサーバーへ
・POSTした内容が正しければ一行目に「SUCCESS」と書かれたデータを返してくる
このPDTデータは
SUCCESS
first_nameJane+Doe
lst_name=Smith
payment_status=Completed
など、1行にひとつ「ネーム=バリュー」形式、NVP形式のデータとなっている。
※ユーザーが支払いを終えて待たずにすぐブラウザを落としたりするとデータ取得できない。購入ありがとうございますページにリダイレクトされてやってきて初めてデータのやり取りが生じる。
PDTデータ取得&解析のサブルーチン
※HTMLデコードと文字コードをutf8にしているところ以外はサンプルコードのまんま。
sub paypal_pdt{
my $self = shift;
my $args = shift;
return if( ! $args->{tx} );
my $paypal = ’https://’ . $self->{paypal}->{server} . $self->{paypal}->{gate};
my $query = join(’&’, "cmd=_notify-synch", "tx=$args->{tx}", "at=$self->{paypal}->{auth_token}");
my $ua = new LWP::UserAgent;
my $req = new HTTP::Request("POST", $paypal);
$req->content_type("application/x-www-form-urlencoded");
$req->content($query);
my $res = $ua->request($req);
return if($res->is_error);
my @response = split("\n", $self->html_decode($res->content) );
my $status = shift(@response);
my %tx;
if($status eq "SUCCESS"){
foreach( @response){
my ($key, $val) = split("=", $_);
$val = Encode::decode(’utf8’, $val) if ! Encode::is_utf8($val);
$tx{$key} = $val;
}
return \%tx;
}
elsif( $status eq ’FAIL’){
return;
}
else{
return;
}
}
PDTデータのpayer_emailやitem_nameなどを「ご購入ありがとうございます」ページの「~様」や「~をご購入いただきありがとうございました」などの個別の表示に使う。
PDTデータのitem_number(商品ID)でダウンロード商品なのか、別の商品なのかを判定して、ダウンロード商品の場合はダウンロードURLを表示する。ダウンロードURLはユーザーのemailやtransactionidなど一意のものから作成している。
4)IPN(Instant Payment Notification)
ユーザーから見える言わば表側のPDTと違って、こちらは裏側。
ユーザーがお支払いを終えると管理ページで指定したURLにデータが飛んでくるので取りこぼしがない。
PDTはユーザーに見せるご購入ありがとうございますページに使う程度で、オレオレサーバーのデータベースに購入の記録を残すためにはこちら、IPNを使う。
図では赤い矢印がひとつだけど、データのやりとりの実際は。
→PayPalからオレオレサーバーへ
・購入データが送られてくる。いわゆるWEBのフォームデータで「&」で繋がれた「ネーム=バリュー」形式
→オレオレサーバーからPayPalへ
・送られてきた購入データにコマンドをひとつつけてPayPalにPOSTする
→PayPalからオレオレサーバーへ
・「VERIFIED」か「INVALID」か一行返ってくる。これ以外は調べる必要があるらしいが滅多になさそうだし、PayPalの管理画面で確認すれば良い。
IPNデータ取得&解析のサブルーチン
エラーはIPNのデータをつけてメールするように。
VIRIFIED(データが正しい)場合でも以下の4点を確認する。
・支払いのステータス「payment_status」が完了「Completed」であることを確認
・すでに完了した取引の悪用防止のために「txn_id」が過去のものと重複していないことを確認
・不正アカウントに支払いされないように「receiver_email」がPayPalアカウントに登録したメールアドレスであることを確認
・価格が変更されていないか確認(商品IDなども)
確認できたらオレオレサーバーのデータベースに必要情報を登録して、ユーザーにお礼とダウンロードURLを書いたメールを送信する(自分にも同じものを送信)
※データ確認の部分やメールの部分以外はサンプルコードのまんま。
sub paypal_ipn{
my $self = shift;
my $args = shift;
my ($s,$ms,$h, $d,$m,$y) = localtime(time); ++$m; $y+=1900; my $ymd = sprintf qq{%s/%02d/%02d [%02d:%02d:%02d]}, $y, $m, $d, $h, $ms, $s;
my $query;
read (STDIN, $query, $ENV{’CONTENT_LENGTH’});
if(! $query ){
print qq{Content-type:text/plain\n\n};
return;
}
$query .= ’&cmd=_notify-validate’;
my $ua = new LWP::UserAgent;
my $paypal = ’https://’ . $self->{paypal}->{server} . $self->{paypal}->{gate};
my $req = new HTTP::Request("POST" , $paypal);
$req->content_type("application/x-www-form-urlencoded");
$req->content($query);
my $res = $ua->request($req);
my %ipn;
my @pairs = split(/&/,$query);
my $count = 0;
foreach my $pair ( @pairs ){
my ($key, $val) = split(/=/,$pair);
$val =~ tr/+/ /;
$val =~ s/%([a-fA-F0-9][a-fA-F0-9])/pack("C",hex($1))/eg;
$val = Encode::decode(’utf8’, $val) if ! Encode::is_utf8($val);
$ipn{$key} = $val;
$count++;
}
my $err;
if($res->is_error){
$err = sprintf qq{%s\nHTTP ERROR: %s\n\n%s\n}, $ymd, $res->status_line, $query;
}
elsif( $res->content eq ’VERIFIED’){
my $msg = $self->update_ipn({ipn=>\%ipn});
if($msg){
$err = sprintf qq{[VERIFIED and Error]%s\n%s\n\n%s\n}, $ymd, $msg, $query;
}
else{
my $body = sprintf(qq{
%s様
「%s」ご購入ありがとうございます。
%spaypal/%s?download=%s
こちらのURLからダウンロードしてください。
・ダウンロード回数は%s回
・ダウンロード期間は%s日
となっています。
よろしくお願いいたします。
});
$self->send_paypal_download({
addr=>$ipn{’payer_email’},
subject=>’【’ . $ipn{’item_name’} . ’】ダウンロードURLのお知らせ’,
body=>$body
});
$self->send_paypal_download({
addr=>$ipn{’root_email’},
subject=>’【’ . $ipn{’item_name’} . ’】ダウンロードURLのお知らせ’,
body=>$body
});
}
}
elsif( $res->content eq ’INVALID’){
$err = sprintf qq{[INVALID]%s\n\n%s\n}, $ymd, $query;
}
else{
$err = sprintf qq{[UNKNOWN ERROR]%s\n\n%s\n}, $ymd, $query;
}
if($err){
$self->send_alert_mail({
addr=>$self->{root_email},
subject=>’[PAYPAL]IPN ERROR!!’,
body=>$err
});
}
print qq{Content-Type: text/plain\n\n};
exit;
}
【ダウンロードについて】
ダウンロードはダウンロード用のスクリプトがファイルを返すようにしてある。
たとえば、わたしが自分だけで作ったコンテンツなんかはどうでもいいんだけど、表紙が依頼原稿だったり、アンソロジーでほかの人の原稿が入っていたりするとそうもいかない。回数や期間を無制限にするわけにはいかない。
なので、ファイルの置き場所=URLをそのままユーザーにお知らせできない。
ダウンロード用のスクリプトを噛ませて
・ダウンロードのURLは購入者ごとに違うものを作る
・ダウンロード回数を制御する
・ダウンロード期間を制御する
といったことを仕込んだ。
また、ダウンロードごとにIPやUserAgentを記録すれば、不正なアクセスやダウンロードできない事故などの問題解決にも役立つ。
以前の雑記にも書いたように、PayPalは管理ページに記録が残ってるし取引が生じたらいちいちメールも飛んでくるので、致命的な問題にはならないはず。サポートもびっくりするというか恐縮するぐらいに厚い。
残念なことに(法律的に?)日本では単純にクレジットカードだけで支払いはできなくなった(ペイパルへのアカウント・会員登録が必須となった)けど、個人での少額決済に手軽に使えるので助かるなあ。
固定レイアウト型EPUBで消耗してるヒマがあったらPDFだろ
ほんとたまたま重なっただけなんだろうけど。先月末ぐらいから今月に入って「固定レイアウトのEPUB3について」という話が飛んでる。
EPUBにパッケージすることで電子書籍市場が広がるので、売ることを考えるならガタガタ言わずにEUPBにするべき。でも、企業のパンフレットやカタログなんかは売る必要もない。ただし、品質的に、レイアウト・デザインは絶対に譲れない。リフローで見た目が違ってくるなんて論外である、という類のものだ。
イラストレーターやインデザインで組まれてPDFに書き出されて印刷されたもの。それを、そのまんま電子書籍で再現してくれ、ということになる。
それって、そもそもEPUBの電子書籍にする必要はあるんだろか。
オーサリングとしてめちゃくちゃ頑張ってテキスト込みで組んだ固定レイアウトのEPUB3ファイルにするにしろ、PDFを画像にして安直な固定レイアウトのEPUB3ファイルにするにしろ、固定レイアウトのEPUB3のメリットが見えないんだよなあ。
印刷に使ったPDFがあるんならそのままWEBに上げてPDFリーダーで読んでもらえば、印刷物そのまんまだし、検索もできるし、それこそ「ふりだしに戻る」だけどプリントアウトもできる。
WEBでPDFを開くのは「PDF注意」などと書かれてるところがあるように、面倒くさいのは確かだ。でも、WEBで固定レイアウトのEPUBを開いて読むのは、おそらくリフローなどとはケタ違いのサイズのファイルを開くことになるだろうから、やっぱり重苦しい。
コーポレートサイトにアクセスしてパンフなんか、その場で見るならともかく、ダウンロードして電子書籍端末やアプリで読むというのも考えにくいだろう。
てことで、固定レイアウト型EPUBファイルのPDFに対する優位性がまるで見えてこない。というかそれ以前に固定レイアウト型EPUBファイルの存在意義すら疑問に思えてきた今日この頃だ。
生徒全員にipad支給というところもあって、教育の現場でibooks、電子書籍に注目が集ってきてるだろうし、実際、教育現場へのICT導入を推進する超党派の議連もあって金が流れ込みそうでもある。教科書なんかは固定レイアウトEPUBの出番なんだけど、無理矢理の電子書籍じゃないかなあ。PDFで何がいけないのかがわからない。
ひとつ利点があるとすると、電子書籍にすれば音声を付けられる。視覚に障害のある子やディスクレイシアの子にとって有用…でも、スクリーンリーダーもあって、そこに読み上げ部分をハイライトさせる機能をつけるのと、音声つき電子書籍の普及とどっちがどっちなんだろか。技術的なことはわたしは素人なのでわからない。
文字を、テキストを読むパッケージとしてリフロー型EPUB電子書籍はこれからの読書環境だと思うし、そうなるだろう。
でもなあ、固定レイアウト型EPUB電子書籍はどうなんだろう、これから頑張れるんだろうか。もっとも、PDFにはもう伸び代もなさそうだし、どっちもどっちなんかなあ。
ちなみに、最近ついったで流れたきた固定レイアウトのネタ
5/13
インデザの固定レイアウトEPUBはそもそもiBooksでの販売しか保障してません
https://twitter.com/JunTajima/status/730976215608135680
5/17
でんでんコンバーターから固定レイアウトをつくってみた
https://twitter.com/nisiumihashiru/status/732218513180352512
5/18
5社全部に配信できる単一の固定型EPUBは作れない
https://twitter.com/ogwata/status/732794535013699588
いやもう固定レイアウト型EPUBファイル制作は「茨の道」である。
(とはいえ、macport経由でImagemagickも無事macにインストールしたので、画像書き出しでOKなら、PDFからの固定レイアウトもどんとこいですよっ/セールストーク)
ちなみに、神保町というか白山通り脇の天ぷら「いもや」だけは間違いがないなあ、と数年ぶりに食って実感。ここの春菊の天ぷらとしじみの味噌汁は鉄板だ。
