

ブログのチューニング

つい先日、このブログ『ひまつぶし雑記帖』をリニューアルしたものの、表示のもっさり感は解消されず。そこは、レスポンシブ対応が最優先だったんであまり考えてなかった。
んで、ひと段落して改めてみると、もっさりしてるのがやっぱり気にいらない、よなあ。
てことで、表示速度のチューニングをしてみた、というのが今回のエントリ。
2013年のエントリにも書いたとおり、WEBは早さが唯一の絶対正義
ここんとこ雑記帖が重い=表示が遅いのでイラっとしていた。ここで何度も言うけど「WEBは早さが唯一の絶対正義」そんな状態なのに、各記事にカテゴリをつけるため、データベースにカテゴリ用テーブル、カテゴリと記事のリレーション用テーブルを追加。そりゃまた当然遅くなる。
最近? SSG(Static Site Generation)、静的ページを生成して公開するサイトが増えてきている(ように見える)のも、セキュリティ的に安全性が高いのもそうだけど、それ以上に表示速度の「ちょっ早」なのが魅力だからだろうなあ。
表示速度改善のために。
まずは直近のエントリを5つ表示するトップページ。
- 表示させる5つのエントリを取得するSQL(1)
- 1つのエントリごとに関連エントリを取得するSQL(5)
- 年/月ごとのエントリへのリンクのためのSQL(1)
- サイドの「最近のNN件」取得のためのSQL(1)
- サイドのカテゴリを取得するためのSQL(1)
と、計9回SQLが走る。
そりゃそうだ、という話なので、トップページはエントリ登録時に静的ページを生成することにした。
トップページにアクセスされたら、静的ページを読みこんで返す。SQLも走らないんで少しは早くなる、はず。
動的に表示させる時にも、表示/閲覧のためだけに「最近のNN件」などの部分でSQLを走らせるのは無駄。このあたりの部品もエントリ投入時に個別で静的ページを生成するようにした。
これで動的ページも少しは早くなる、はず。
実際に確認したところ、体感できる程度には早くなった、ような気がする。
…けど、時間帯で表示されるまでの時間が違う、ような気がする。ひょっとするとレンサバのスペックが関係して、混み合う時間帯なんかはこちらでどうこうしてもしかたない、のかもしれない。
とはいえ、やれることはやってみるかな。
動的ページ、エントリひとつのページなんかで、SQLが走るところがある。少しずつ部品ごとで検討しよう。
ちなみに。
今日時点で、SSGとして人気なのは以下の3つらしい。
・Hugo
・Astro
・11ty
https://github.com/11ty/eleventy
(※ 雑にぐぐってみただけ)
今からブログを作ってみよう、と思われるのだったら、静的ページで運用展開することをオススメします。ウチのブログと違って、ポチっとアクセスして、即表示されるページ・サイトはやっぱり気持ちいいですよ!

同じレンサバで公開してるホームページ 『On Golden Pond』は全部静的ページで表示はめっちゃ早い。てことを考えると部分的に静的ページにしたところで、時間帯によってperlのパフォーマンスが低下したりするのかなぁ。
画像サイズを旧ブログよりもちょっと大きくても大丈夫にしたから、それも影響がある、かもしれない、かなぁ。
[02/25 11:01:17] この写真サイズにして改めて見ると水面の質感とかこってり出てるなあ。おもちゃみたいな単三電池で動くコンデジ(KODAK PIXPRO FZ45)が去年のベストバイだ。
オレオレMarkdown

わたしはMarkdownなんちゃらが大嫌い。
そもそも、Markdown記法など、みっともないし綺麗じゃない。宗教上の理由とか生理的嫌悪と同じ。異論は受けつけない。
というのが今回のエントリ。
Markdownという記法で記述されたものはHTMLに変換される…え? だったら最初っからHTMLで書けよ、だ。
シンプルな記号で文章構造(見出し、リスト、強調など)を簡単に表現でき、特別なソフトなしで読み書き可能で、HTMLへの変換も容易なため、議事録、ブログ、仕様書作成など幅広い用途で生産性が向上することです。
ということらしい。
嘘をついちゃいけない。Markdownを覚える学習コストもHTMLを覚える学習コストも大きな差はない。
HTMLは30年以上前に完成された記述方法で今でも使える。これが原点で原典。
仕様やタグが追加されたりしながらも、記述方法そのものは変わらない。
それに対して、MarkdownはHTMLの被せものなので、その書きかたに、いつどんな変更が入るかわからない。
どこかのプラットフォームの都合で使いものにならなくなることが十分考えられる。つまり、今、Markdownに学習コストをかけたところで無駄。
だいたい、テキストを書いていて半角記号が文書構造の一部を指定することになるなんて、見た目からして気持ち悪くないか?
なにその意味不明な「#」「**」「-」
「えぇ…っと、ここでこの半角記号書いちゃっても大丈夫なんだっけ」だよね。
文章、テキストを書いていて余計な気をつかう必要があるってどゆこと?
その点HTMLのタグは「<タグ開始>」テキスト「</タグ終了>」という記述で、タグに記入されている半角英数字は文書指示ですよ、というのが明確。
今日の予定
最優先は 特売の豚こま 忘れないように!
#今日の予定
最優先は **特売の豚こま** 忘れないように!
<h1>今日の予定</h1>
最優先は <strong>特売の豚こま</strong> 忘れないように!
文章、テキストを書いてる時は「書いている内容」に集中したいし、集中できるようになっていてしかるべき。
文書の指定なんて後から入れればいいだけの話だ。
見た目についても、Markdownを使いこなしてレイアウトデザインも凝った表現ができたとして、それはそれでどうなんだ?
そんなに方眼紙エクセルが好きか?
レイアウトデザインで多彩な表現をしたいならHTMLとCSSを使うべき。
Markdownで書かれたテキストはそのままテキストとしても見える/読める/使える、というメリットがあるらしい。
日本語の文章で? それはない。くり返しになるけど、書いてる時の混乱と同じ。
読む時も「なにその「#」とか「**」とか? タイプミス? 誤植? 校正漏れ?」にしか見えないから使えない。
みっともないと思わないんだろか。
本文の余計なものを削除する場合。
HTMLのタグなら簡単なのに、Markdownの記号は本文中に紛れこむから面倒なだけ。
書く時も邪魔なら、読む時も邪魔なのがMarkdownというしかない。
↓ Markdownの問題点がわかりやすい
日本語でのマークアップ記法としては「青空文庫記法」が1998年ぐらいからあって、小説などの日本語テキストを書くには、たぶんこれが最強。
https://www.aozora.gr.jp/aozora-manual/index-input.html
日本語の文章に混じりこんでいて「注釈」=意味として成立していて読める。Markdownの半角記号類より違和感も少ない。
てことで? このブログ『ひまつぶし雑記帖』で、入力されたテキストを適当に変換するオレオレMarkdown。
入力されたHTMLタグは素通し。
(フォームデータの入力経路にちょっとした振り分けを仕込んでいて、振り分けられた側の入力データは洗浄してる。そもそもエントリ入力はログイン状態が前提なのでセキュティ的に特に問題はない)
ルールは簡単で
「入力されたテキストは一行ごと(改行ごと)に「pタグ」で包まれる」
だけ。
このルールを適用されると困るものは一時的に退避して復元する。
素通しで入力されるHTMLタグなんかもこの対象として扱う。
$to_hexでタグ文字列を16進数に変換して
$to_strで元のタグ文字列に戻す
my $to_hex = sub{ my $s = shift;
return unpack("h*", Encode::encode('utf8', $s));};
my $to_str = sub{ my $s = shift;
return Encode::decode('utf8', pack("h*", $s));};タグを抽出して退避
$flg->{'html-tag'} = ( $body =~ s!<([^>\p{Han}\p{Hiragana}\p{Katakana}]+)>!sprintf(qq{_LT_%s_GT_},$to_hex->($1))!eg );退避されたタグを抽出して復元
if( $flg->{'html-tag'} ){
$body =~ s!_LT_([0-9a-f]+)_GT_!sprintf(qq{<%s>},$to_str->($1))!eg;
}最優先は <strong>特売の豚こま</strong> 忘れないように!
↓タグを退避 ↑タグを復元
最優先は _LT_374727f6e676_GT_特売の豚こま_LT_f2374727f6e676_GT_ 忘れないように!
結局HTMLで書くのが早いし確実。
Markdownで解決/実現できない表示についての対処方法が「生のHTMLを書く」となっているのは何の冗談なんだか。
まずHTMLありき。Markdownが滅んでもHTMLが滅ぶことはない。
とはいえ。
マークアップがどーしたとか言ったところで、肝心の文章がつまらないんじゃしょうがないですね。すみません。

それでもブログは続けられる
今回のエントリは前回の続きというか
ごちゃごちゃ書いておいて実際のとこ、それどうなの?というと個人サイトはほとんど見られない。
てことの補足蛇足
誰も見ないようなホームページとかブログとか、そんなのやってて何になるの?
今日はページを作った! とか、ブログのエントリをひとつ書いた! とか達成感を得られて、それが自己肯定感に繋がる。というのがすべて。
今日は1万歩には足りなかったけど8000歩は歩いた! とか、スーパーで美味しそうなブリの特売を見つけて買うことができた! なんかと同じこと。日常のちょっとしたことにも達成感は見つけられる。
自己肯定に通じるルートは広く多いに越したことはない。ブログやホームページ、個人サイトがルートの1つになってるから続く。
ロープレやっててレベルアップとかスキル獲得とか目の前の達成感が楽しい。ご褒美があるからラスボスまでたどり着ける。
誰にも見られないのに?
それは、達成感とは関係のない話だってばよ。

インターネット辺境の個人サイト生活
レンタルサーバーで自分のスペース(居場所)を確保して、ドメイン(名前)を取得して、インターネットで遊ぶのは楽しいし、なによりほぼ自分の管理下なので安心安全でいいよねー
というのが今回のエントリ、というか公開してる自分のサイトの棚卸し&自画自賛。
わたしが「doncha.net」という個人サイトを始めたのは、2007年4月。
ロリポップでレンタルサーバーの契約をして、ムームードメインでドメインを取得。20年ぐらい続いている。
費用(今日時点)
ドメイン:税込2318円(一年)
レンタルサーバー:330円(一ヶ月)
ざっくり毎月500円ちょっと。
ブログサービス、各種プラットフォームをうまく利用すれば無料でまかなえるけど、XやFacebookのタイムラインそれでいいの?とか、自分で投稿したテキストをエクスポートできないって?とか、もろもろ制約も多いことだと思う。
その点、毎月500円程度、追加なしの牛丼一杯ぐらいのお値段で、ホームページ、ブログ、SNS、web本棚とインターネットで自分の好き放題に使えて遊べる居場所を確保できるんだから安いんじゃないかな。
以下、公開してる個人サイトを古い順に。
【ブログ】
『ひまつぶし雑記帖』1998〜
このブログ。
これはレンタルサーバー以前、最初はプロバイダのホームページ「public_html」以下のURLに「~」がつく「ニョロホームページ」でスタート。HTMLを書いてFTPでアップロードしてたのをperlによるCGIにリニューアル。さらにレンタルサーバーに移って今のいわゆるブログ形式にした。
ブラウザで管理画面を開いてテキストエリアに入力、画像のアップロードやカテゴリ付けも同じ画面で完結する。
ブログとはなんぞや、みたいな話は知らないけど、CMS(?)のお手軽さはいいよねえ。
小学校の頃の日記なんか、それこそ三日坊主だったのは書くことがないのもそうだけど、日記を書くための準備が面倒くさかったから。
今だと毎日パソコンを立ちあげてごそごそしてるわけで、「ついでに」ブログ(雑記・日記)を書く動線が目の前にある。
エントリの内容は…基本ヨタ・ネタ・譫言がほとんどだけど、ライフログとかいうそれっぽい言い方もあることだし自分的にはギリOK、かなぁ。さすがに20年前ぐらいは昭和平成で、21世紀の今からするとアウトのものが多いけど「発表当時の世相を反映しております」てことで。
【web本棚】
『趣味は読書2』2006〜
本棚共有サイトとして2006年にサービス公開。わたしの年齢的なこともあり、継続するのも限界が近いので新規登録を終了。レンタルサーバーの契約更新のタイミングで終了の予定。登録ユーザーさん向けに各自の本棚を復元するスクリプトを作って案内した。
『web本棚』2026〜
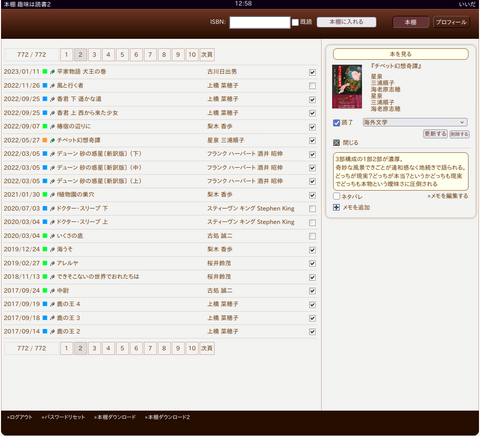
上記の『趣味は読書2』で作った復元スクリプトで自分のweb本棚を公開した。
この本棚は、本をダブって買うことのないようにチェックするため、というのがスタート。いまや電子書籍になって「購入履歴」で確認できるので役割終了。さらに電子書籍は付箋やメモもつけられて便利な機能が満載だし…と思いつつ、自分の使い勝手で機能をつけてきて馴染んでる、使いやすい。
それに、本棚って、眺めるだけで楽しくなるのはわたしだけじゃないと思う。
老眼がすすんで文庫本の小さな文字サイズがつらくて読書量も激減してるんだけど、つい先日、老眼鏡を作ったのでふたたびみたびこの本棚の出番となった。
ActivityPubを喋ってフェディバース経由で自分の本棚を検索できるようにしたので、自分専属の司書さんみたいなもの。
ホームページの方にソース公開
『web本棚のソースコード::On Golden Pond』
https://www.doncha.net/monooki/bookshelf.html
『web本棚ActivityPub対応部分のソースコード::On Golden Pond』
https://www.doncha.net/monooki/bookshelf-activitypub.html
【SNS】
『ため池::ところてん』2023〜
https://tokoroten.doncha.net/t2aki
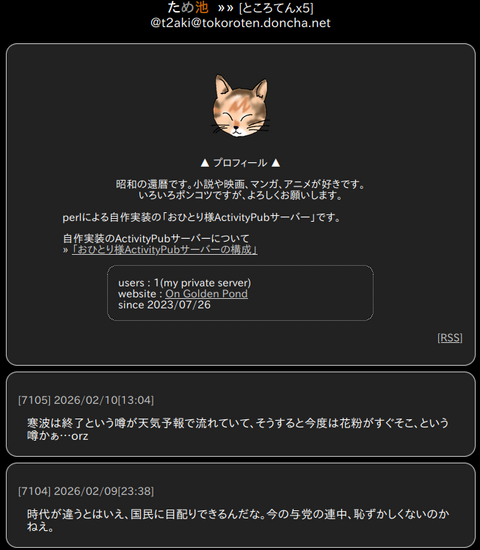
X(旧ツイッター)がごちゃごちゃになった2023年ごろ、(わたし的には)27歳で猫が亡くなったことも重なり、時間もぽっかり空いたので、SNS環境を変えようとActivityPubの実装をした。
それまで登録していたX、Facebook、instagram、mixiから撤退。アカウントをすべて鍵アカにして塩漬け(blueskyやmixi2にも登録したけど、これらも結局塩漬け)
タイムラインが時系列になってるだけで、なんの意図も恣意もないものは、XやFacebookなんかとはまったく別もの。って、元ツイッターがそうだったんだけどねー。
居心地がいいので入り浸り。
ActivityPubの実装についてホームページで随時公開
『おひとり様ActivityPubサーバーの自作実装::On Golden Pond』
https://www.doncha.net/activitypub.html
【ホームページ】
『On Golden Pond』2024〜
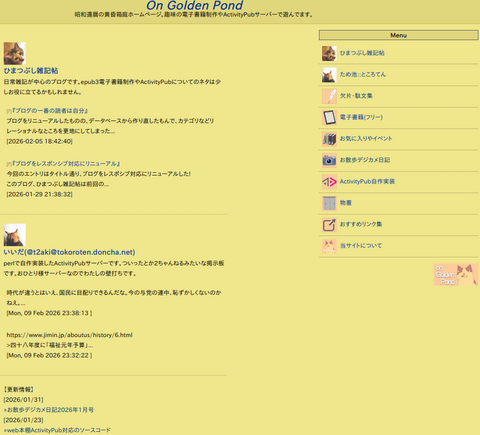
ブログ『ひまつぶし雑記帖』はもともと日本語の文章、テキストを流しこむことが大前提。
なので、perlのスクリプトやcssなんかを表示させるのに向いてない。すべてのエントリでレイアウトデザインも同じになる。って、当然。
biglobeやinfoseekで「ホームページ」を作ってた頃のように、素のHTMLを書いた静的ページをFTPでアップロードする「ホームページ」を作りたくなった。
ペラ1枚で表示もちょっ早だし「HTMLをそのまま」なのでページはなんでもありの自由を満喫できる。実際作ってみてそこが面白い。
ヘッダ部分など、訪問するひとには見えない・関係のないところはスクリプトでつけるようにオレオレMovableTypeにしたけど、本文はエディタで書いていく。
ページを作るのが面白い・楽しい。
『20世紀型個人ホームページの効能::On Golden Pond』
https://www.doncha.net/favorite/20241201-adventcalendar.html
以上が今のわたしのインターネット生活。というか自給自足の自作自演生活。
ごちゃごちゃ書いておいて実際のとこ、それどうなの?というと個人サイトはほとんど見られない。
ホームページはbot、crawlerを除く「人間のアクセス」は一日一桁程度。
ブログも似たようなもんだけど、こちらは25年ぐらいやっていてページのボリュームがある分、ホームページよりはマシ。EPUB3電子書籍がらみのエントリは今でもそこそこアクセスがある。とはいえ、アクセスの多いエントリでもせいぜいふた桁だけど。
個人ホームページは自分が満足できればそれでOKという納得がなければやってられない。
個人ブログは、今だったらnoteなどのひと通りの多いプラットフォームを利用する方が確実に読まれる。個人でブログをやるのはやっぱり自分のため。
といった大きなデメリットがあるんだけど、全部が自分のもので自分の好き放題になるというメリットには敵わないと思う。
オーナーのオモチャにされたり、企業のエサにされたり、自分のコンテンツなのにダウンロードできなかったり、そんな理不尽なことはあってはいけなくて。
自分のコンテンツが自由に独立しているというのは当たり前のこと。
あと。無職還暦爺いの趣味としては金もかからなくてお手軽気楽なのがいいよねー。全部perlで自作実装なので呆け防止になるし。
[更新]2026-02-13 02:24:17
ブログをレスポンシブ対応にリニューアル
今回のエントリはタイトル通り、ブログをレスポシブ対応にリニューアルした!
このブログ、ひまつぶし雑記帖は前回のエントリに書いたように、もはや前世紀の遺物。
いちおう、スマホ対応はしてたとはいえ、UserAgentを見ていろいろ振り分け。このUAを見るというのは、どうやらそろそろ限界らしいという噂がここ何年も続いてた。
今どきのレスポンシブ対応にしておかないとまずいなあ、と思ってたんだけど気が重くて放置状態だった。
最近、個人ブログを読むのが楽しくなってきていて
↑こちらからいろんなひとのブログを訪問してる。
みなさん、情報も適当適切だし、レスポンシブだし、それと比べるとウチはとっちらかってるし…というのを思い知らされたり。
てことで、ブログを作り直すことにした。
レスポンシブ対応が一番だけど、20年ものだしあちこちガタガタ。
特にデータベースは、ド素人。スクリプトを見るとalter table addなんちゃらがあちこちにあってのけぞる。
とはいえ、素人なりにいろいろ考えてたらしい自分はちょっと頑張ってたかも。
最初は新しく作って過去の遺物は廃棄、と思ってたんだけど、昔の自分に止められて過去分を引き継いでリニューアルということにした。
今は亡きツイッターだのfacebook、mixi対応までしていてスクリプトのあちこちに産廃、ガレキの山もあって、これらも掃除するいい機会だ。
データベースを新規に作ると、今までのURLにも影響する。
SEOというやつがもはや意味をなさないらしいんで、気にすることもない。ただ、リンクを貼られてるエントリもあるんで、対応は必要。
rewrite ruleでやると、身動きできなくなることも考えられるんで、スクリプトに仕込み。
久しぶりにSQLを書いたのは、ボケ防止になったかも。perlは相変わらず面白いし。
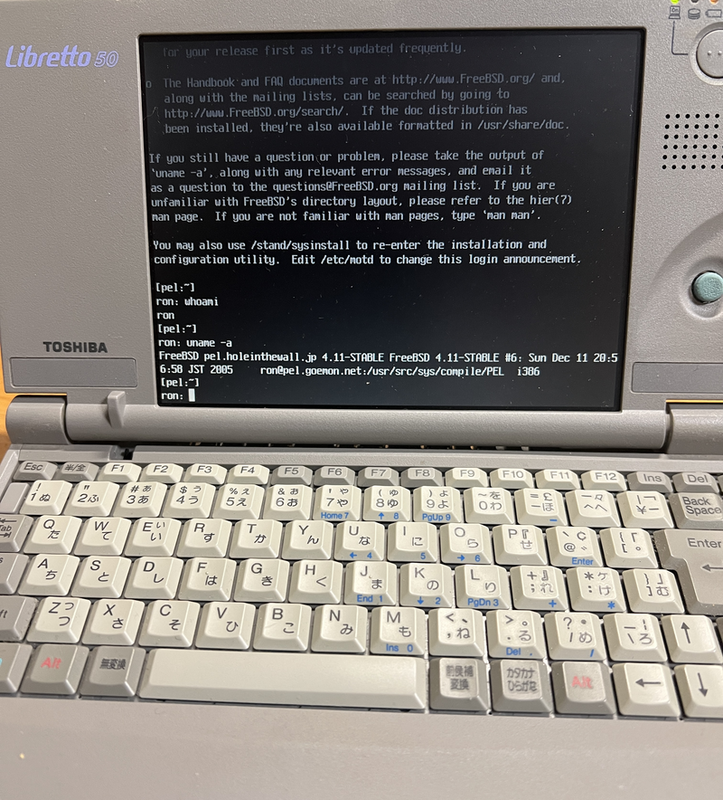
30年ぐらい前にLibrettoを自宅サーバーにして公開してたこともあったなあ