

国立国会図書館のOCR Liteを使ってみる

サンリオSF文庫が読める国立国会図書館のデジタルアーカイブ。
国立国会図書館のデジタルアーカイブの本をOCRして(?)テキストを引っ張り出す、というのが今回のエントリ。
先日書いたように、これは各ページを画像として保存したもの。WEBで読みやすいようにページが工夫されてるんだけど、やっぱり手元、ローカルで気軽に読みたい。老眼に優しく文字サイズも調整できるepub3電子書籍にしておきたい。
そのためには「画像で保存されている文章」をテキストにする必要がある。そしてなんと!国立国会図書館では画像で保存されている文章をOCRによってテキストにするツールを公開してくれている。
NDLOCR-Liteアプリケーションのリポジトリ
https://github.com/ndl-lab/ndlocr-lite
↑ こちらの
https://github.com/ndl-lab/ndlocr-lite/releases
「release」から、最新版のv1.1.3
「ndlocr_lite_v1.1.3_linux.tar.gz」
「Source code (zip) 」
をダウンロード。
まずは「ndlocr_lite_v1.1.3_linux.tar.gz」を適当なディレクトリに解凍。
「linux」というディレクトリに展開される。
linux
├── data
├── lib
├── ndlocr_lite_gui
├── python3.12
└── site-packagesこの中の「ndlocr_lite_gui」という実行属性のついたファイルをコマンドラインで叩くと立ち上がる。

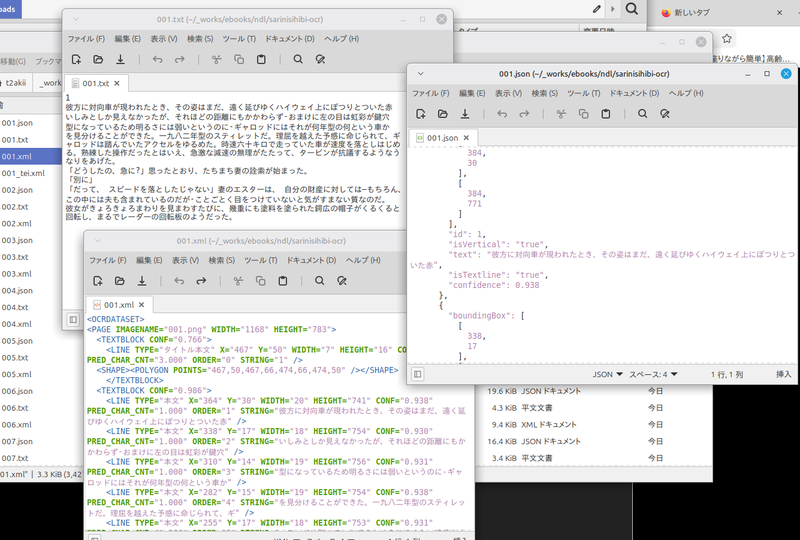
デジタルアーカイブの画像をスクリーンショットして溜め込んだディレクトリを指定してOCRを実行すると、アウトプット用に指定したディレクトリに「テキスト」「JSON」「XML」の3種類のファイルが保存される。
今回114枚の画像で、だいたい17分ぐらい。
PCはMac mini Mid 2011
OSはLinux Mint
・ルビや圏点は反映されてない(?)
・JSONやXMLにはレイアウト、位置情報が入ってるっぽい。
epub3の電子書籍にするので、テキストだけで問題はない。ルビや圏点がなくても、わたしは大丈夫。そのうちきっと解決してくれると思う他力本願寺。
これだけでテキスト化できて、操作画面を見ながらこまかい指示を必要ともしないんで、コマンドラインで実行できるようにした。
ただ、わたしはpythonについてまったく知らなくて、何かあったら困るので調べ物。
「Source code (zip) 」を適当なディレクトリで解凍する。
「ndlocr-lite-1.1.3」というディレクトリ以下に展開される
ndlocr-lite-1.1.3
├── LICENCE
├── LICENCE_DEPENDENCEIES
├── README.md
├── dummy.dat
├── ndlocr-lite-gui
├── pyproject.toml
├── requirements.txt
├── resource
├── src
└── train展開されたディレクトリに移動して以下のインストールが必要。
ndlocr-lite-1.1.3$pip install -r requirements.txt
ということだけど、わけもわからずインストールして、現在の環境に変な影響が出たら困る。
pythonは仮想環境で利用する(?)こともできるとのことなので、仮想環境を使うために以下をインストール
ndlocr-lite-1.1.3$sudo apt install python3.12-venv
インストールが終わったら
ndlocr-lite-1.1.3$. .venc/bin/activate
と叩いて仮想環境に入る
→コマンドプロンプトの左端に「(.venc)」と表示される。
(必要なものは「.venc」ディレクトリにインストールされるっぽい)
仮想環境に入ったことを確認して、上記の「pip」コマンドで必要なものを改めてインストール
「ndlocr-lite-1.1.3/src」ディレクトリに移動してndlocr-liteのpython3のコマンドを叩けばOK
- --sourcedir
スクリーンショット画像の入ったディレクトリ - --output
テキストなどが出力されるディレクトリ
各ディレクトリはどこでも大丈夫。わたしは相対pathで指定した。
ndlocr-lite-1.1.3/src$ python3 ocr.py --sourcedir ../../image-out --output ../../_tmp
コマンドラインの方が気持ち早かった…かも。
指定したディレクトリにGUI版と同じものが出力されていた。
作業が終わったら仮想環境を抜ける。
ndlocr-lite-1.1.3$deactivate
テキストにさえなってれば電書化はそれほど難しくない、かな。
…冒頭一字下げや空行がなくなってるんで、そのあたりの判定をどうにかしないといけない。
とはいえ。
これで、絶版となって今は読めないサンリオSF文庫が読み放題だ!!
今回、真っ先にテキスト化したのは、ボブ・ショウの『去りにし日々、今ひとたびの幻』
https://dl.ndl.go.jp/pid/12632736
これが読みたかったんだよなあ。スローガラスというアイディアから広がるドラマがたまらない傑作。
ちなみに、この作業の中でページのスクリーンショットを撮るには。
個人向けデジタル化資料送信サービス
https://www.ndl.go.jp/use/digital_transmission_individuals
わたしは「本登録」済みなので
>「公開範囲」が「送信サービスで閲覧可能」「国立国会図書館内/図書館・個人送信限定」
の本は「印刷」できる=PDFファイルとしてダウンロードできる。
※一回100コマまで
PDFにすればあとはImageMagickの出番なんだけど、今日時点コマンドがよくわからないんで、手作業で1ページずつスクショしたというテイタラク。
これはまたそのうち、だなあ。
そういや。
「OCRする」って、「インターネットする」と似てるような…
OCRって「する」ものなんだろか。言葉を雑に扱ってる自覚はあります、すみません。